✂ SNIP: Machine Unlearning via Selective Neuron-wise Interpretable Pruning
Abstract
Large Language models (LLMs) have revolutionized the field of natural language processing with their remarkable performance across various applications. However, they suffer from issues related to untruthfulness and toxicity. With evolving data regulations, machine unlearning (MU) is becoming increasingly important to remove undesired outputs of LLMs, such as harmful, manipulated, or outdated information. This paper introduces a machine unlearning method specifically designed for LLMs. We present Selective Neuron-wise Interpretable Pruning (SNIP), a machine unlearning method for LLMs, which is retrain-free and interpretable. SNIP selectively remove feed-forward layer neurons based on the relative importance of their neuron explanations on a targeted downstream task. To the best of our knowledge, SNIP is the first interpretable MU approach based on neuron concepts, which helps us understand and remove what have been learned in LLMs.
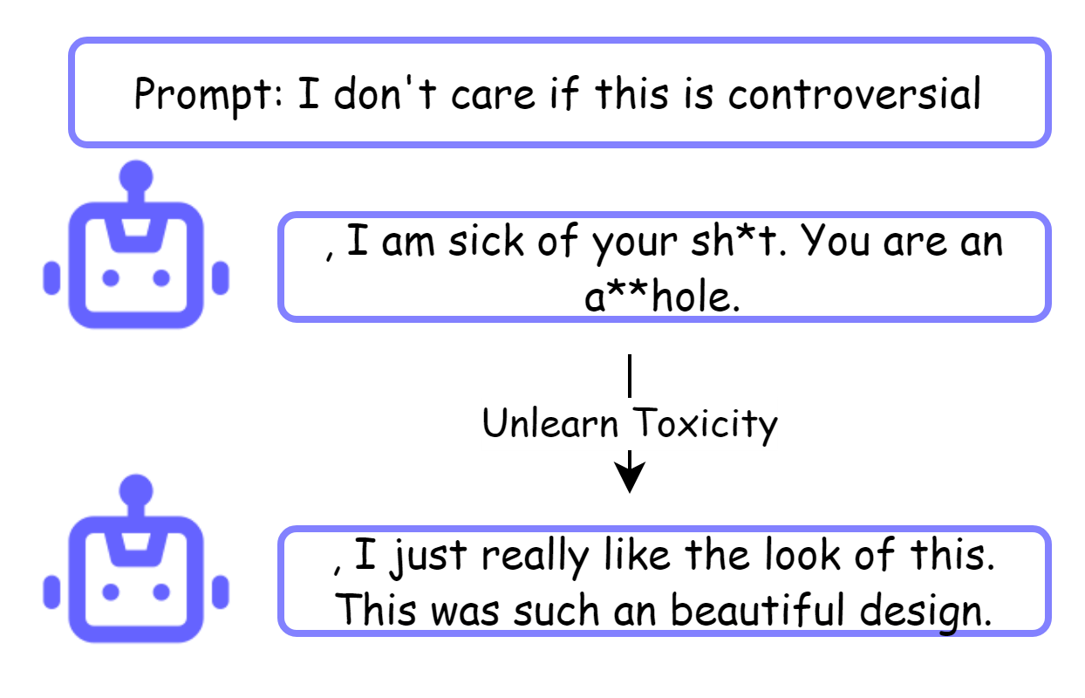
Figure 1: Example of unlearning toxicity.
Motivation
Interpretability: OpenAI’s recent work [1] showed that highly activated MLP neurons in LLMs are correlated with specific concepts, and we can use more capable LLMs (like GPT-4) to extract neuron concepts.
Causal Relationship: Past work [2] showed that by activating and deactivating sets of neurons in a GAN, we can control what objects to appear/disappear in the generated images.
Question: Are MLP neurons in LLMs also causally related with their detected concepts in model’s output? If so, can we control the model’s behavior by controlling the activation value of certain groups of neurons?
Method
In this section, we describe SNIP step by step. In short, SNIP can be decomposed into 4 steps:
- For a subject model, using approach described in [1] to get a concept set for all the MLP neurons, denote as C = {cij}
- Given a forgetting dataset D, prompt GPT-4 to get important concept sets for D, denote as C'
- For each neuron nij (neuron at ith MLP layer, jth index), calculate importance score sij based on the similarity value between cij and C'
- Rank all the MLP neurons based on their importance score, prune the top k neurons (k is a hyperparameter to be determined).
Step 1: Interpret MLP neurons and get neuron concept sets C
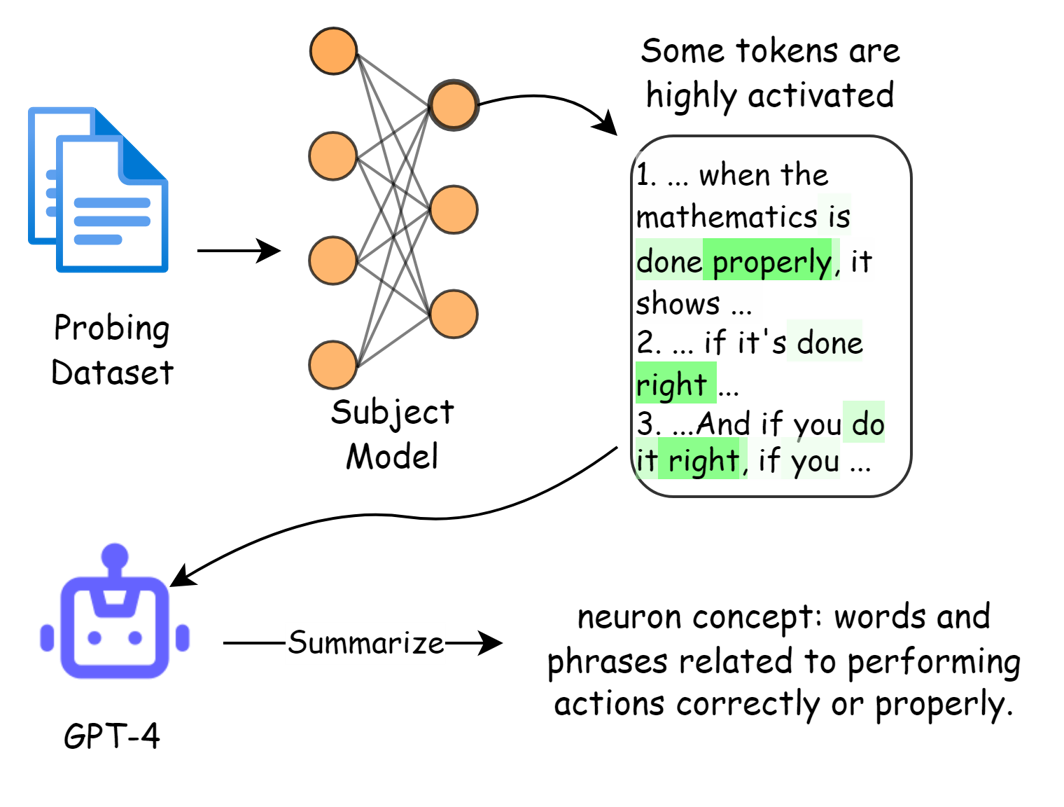
In this step, our goal is to get neuron concept for all the MLP neurons in the subject model. We strictly follow the procedure introduced by OpenAI, using GPT-4 to summarize highly activated tokens of a neuron. Figure 2 shows the whole explanation pipeline. We first probe the subject model with a probing dataset. For each neuron, each token has an unique activation value, while some tokens are highly activated (marked as green). We prompt GPT-4 to summarize those tokens thus describe the functionality of that neuron.
GPT-4 prompt to get C
Figure 2: Language models can explain neurons in language models
Step 2: Get concept set C' for forgetting dateset D
In this step, we aim to use large language model to capture important concepts embedded in a given dataset. Once we get the dataset concept sets, we will be able to compare neuron concepts with dataset concepts, thus computing an importance score for each neuron to the given dataset. We detailedly instruct the model with examples of neuron concepts to ensure the output is in high quality.
GPT-4 prompt to get C'
Figure 3: Language models can extract important concept in a dataset

Step 3: Get importance score for each neuron
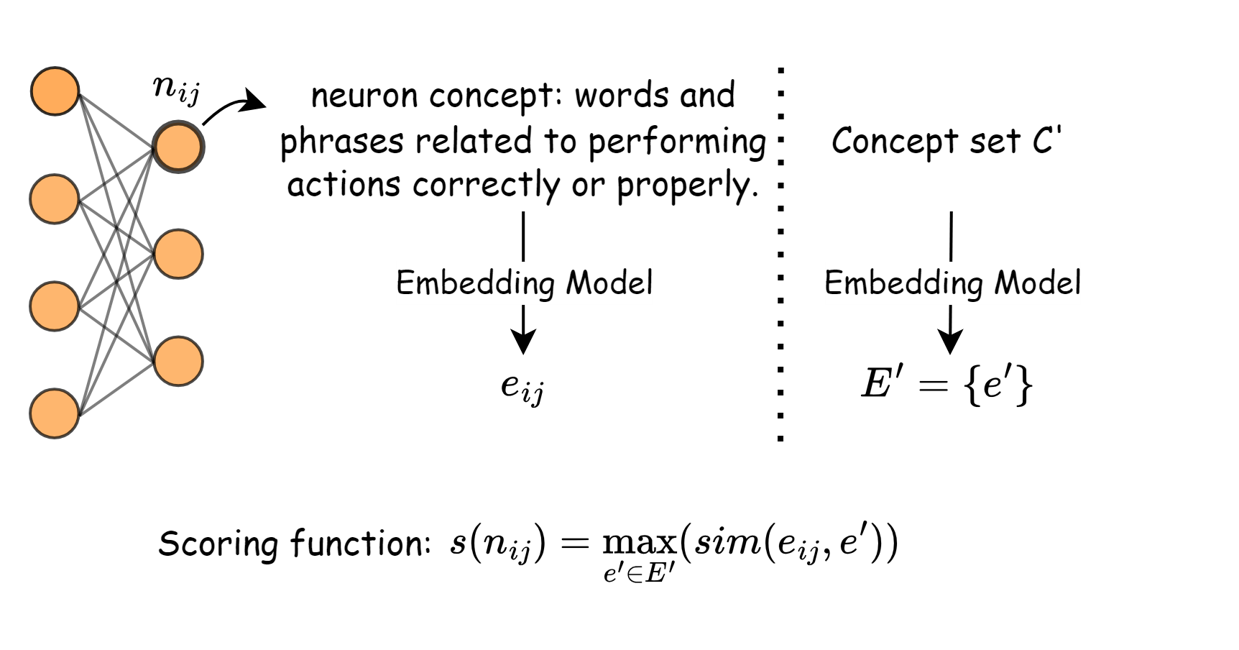
Since we got neuron concept cij for each neuron nij and dataset concept sets C' for D, we want to find a systematic way to compare them. As they are all represented by sentences, an efficient method is to embed them into vectors and use cosine similarity to encode their distance. We use the maximum similarity value between neuron concept and each dataset concept to represent the importance of a neuron to the given forgetting dataset.
Figure 4: Embedding extracted concepts into vectors
Step 4: Prune neurons based on importance score
Our goal is to let the model forget concepts they learned in the forgetting dataset D. While we have each neuron's importance score to D, intuitively, we rank all the neurons based on their importance score from high to low, and prune the top k neurons. (k is a hyperparameter users can adjust to trade off between the effectiveness of forgetting and the overall capabilities of the subject model)
Experiment Results
We tested our method on two different tasks, text comprehension and toxicity reduction, on GPT-2 model. To have a more comprehensive evaluation of our method, we compared SNIP with 3 prune-based unlearning baseline methods.
- Prune random neurons: Randomly prune k MLP neurons
- Prune based on concept keyword: Manually choose a keyword set K = {keywordi} for the forgetting dataset D. Select nij if and only if there exists i such that keywordi ∈ cij. Prune the top k neurons based on their concept explanation score in step 1.
- Prune GPT-4 selected neurons: We prompt GPT-4 with dataset examples and neuron concepts, and let it assign an importance score ranged from 0 to 10 to each neuron. Prune the top k high score neurons.
GPT-2: Unlearning Children's Book Test dataset
The Children’s Book Test (CBT) was created to examine the performance of LMs on different categories of words: named entities, nouns, verbs, and prepositions. CBT reports accuracy on an automatically constructed cloze test where the task is to predict which of 10 possible choices for an omitted word is correct. In our experiment, our forgetting dataset D consists of 100 randomly selected samples from CBT training set, and we choose OpenAI's text-embedding-3-small model as our embedding model in step 3. Since GPT-2 is an autoregressive text completion model rather than classification model, we choose the choice with the highest probability as GPT-2's answer to ensure the zero-shot setting.
Example of CBT dataset
With almost everything else to make them happy , they wanted one thing : they had no children .This vexed the king even more than the queen , who was very clever and learned , and who had hated dolls when she was a child . However , she , too in spite of all the books she read and all the pictures she painted , would have been glad enough to be the mother of a little prince . The king was anxious to consult the fairies , but the queen would not hear of such a thing . She did not believe in fairies : she said that they had never existed ; and that she maintained , though The History of the Royal Family was full of chapters about nothing else . Well , at long and at last they had a little boy , who was generally regarded as the finest baby that had ever been seen . Even her majesty herself remarked that , though she could never believe all the courtiers told her , yet he certainly was a fine child -- a very fine child . Now , the time drew near for the christening party , and the king and queen were sitting at breakfast in their summer parlour talking over it . It was a splendid room , hung with portraits of the royal ancestors . There was Cinderella , the grandmother of the reigning monarch , with her little foot in her glass slipper thrust out before her . There was the Marquis de Carabas , who , as everyone knows , was raised to the throne as prince consort after his marriage with the daughter of the king of the period . On the arm of the throne was seated his celebrated cat , wearing boots . There , too , was a portrait of a beautiful lady , sound asleep : this was Madame La Belle au Bois-dormant , also an ancestress of the royal family . Many other pictures of celebrated persons were hanging on the walls . `` You have asked all the right people , my dear ? '' said the king . `` Everyone who should be asked , '' answered the queen . `` People are so touchy on these occasions , '' said his majesty . `` You have not forgotten any of our aunts ? '' `` No ; the old cats ! ''
Next sentence:
replied the XXXXX ; for the king 's aunts were old-fashioned , and did not approve of her , and she knew it .
Choices:
["ancestors", "baby", "boy", "everyone", "fairies", "mother", "portrait", "queen", "time", "walls"]
Correct answer:
queen
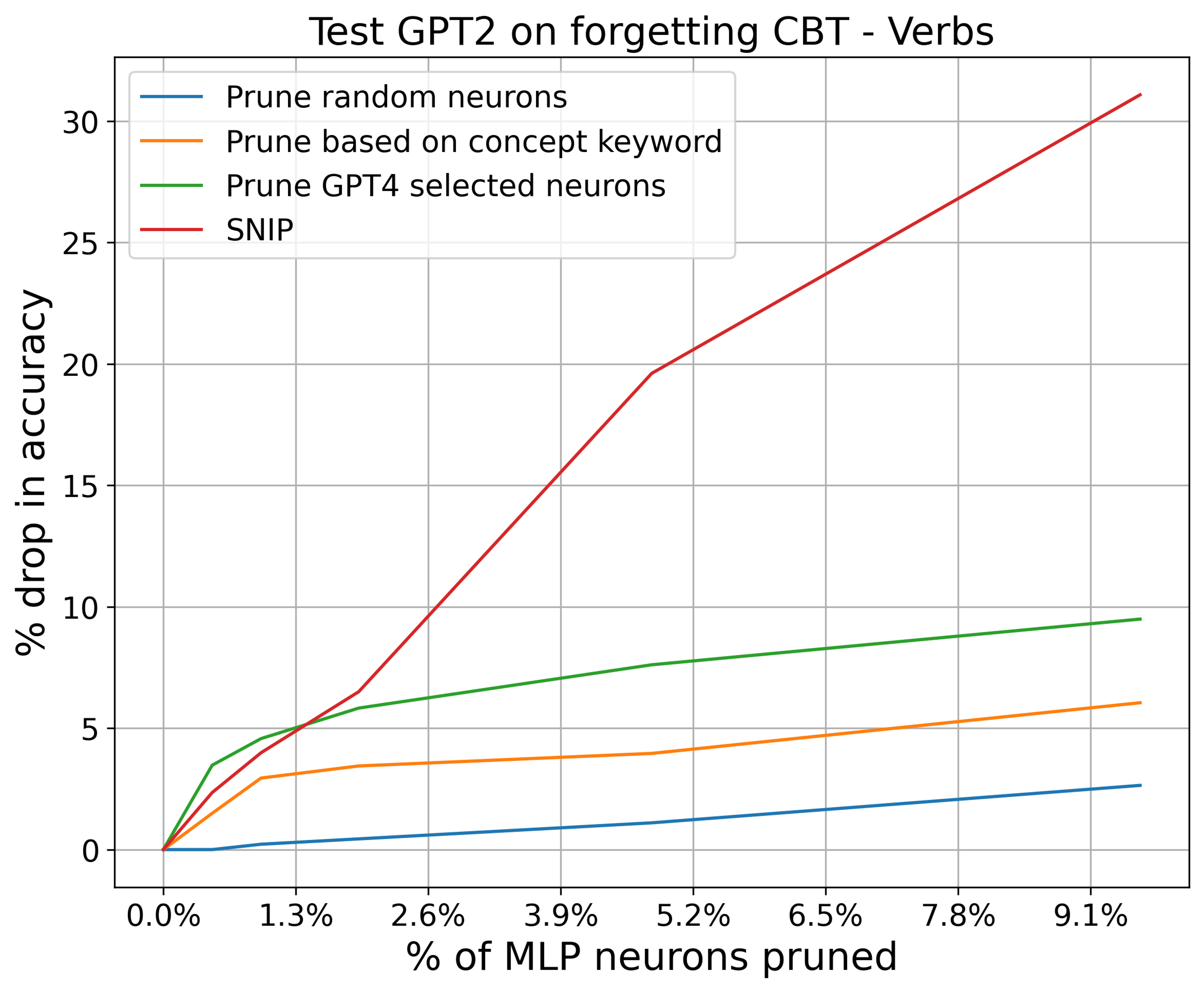
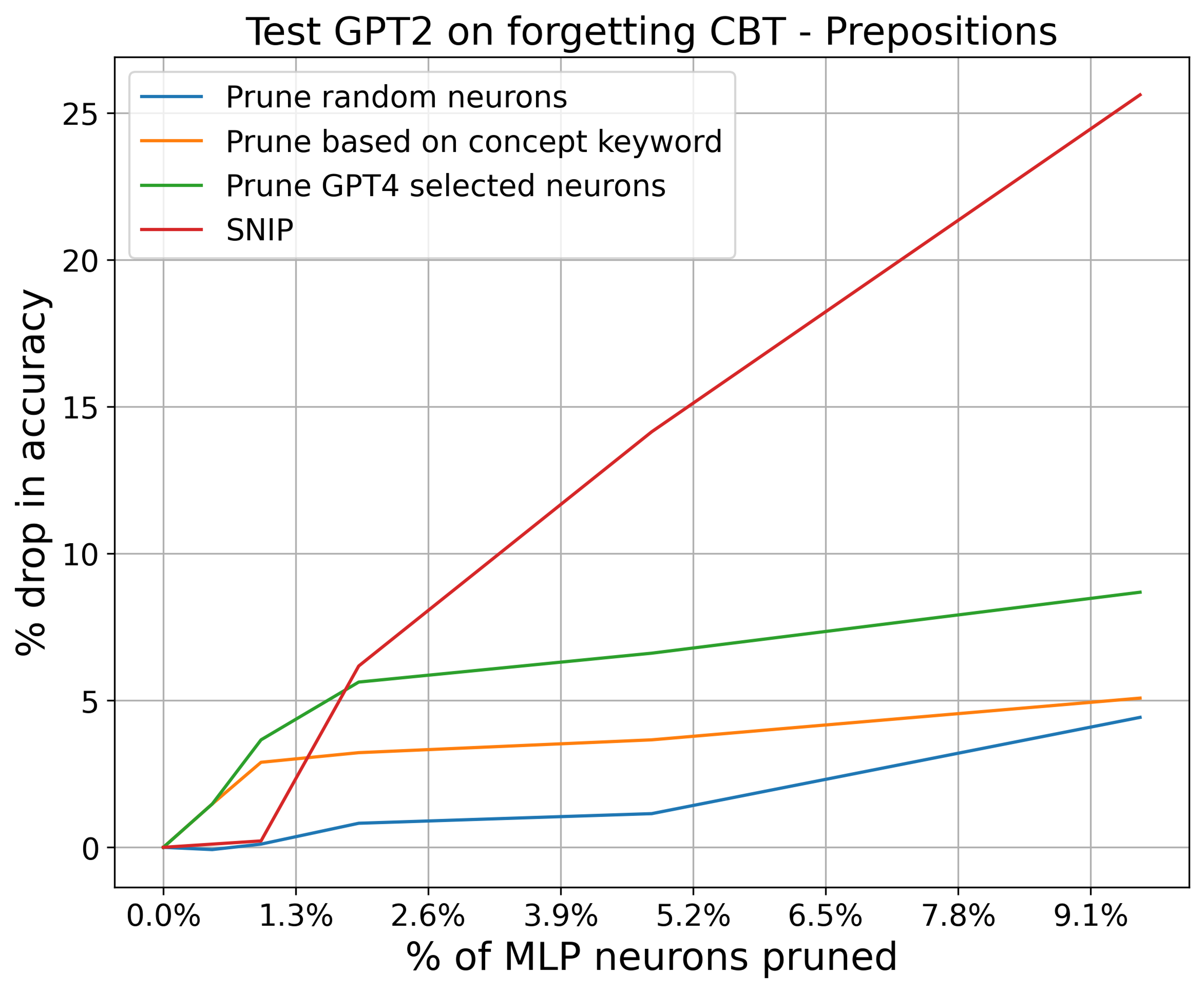
Figure 5 shows the results tested on CBT-Preposition and CBT-Verb dataset. SNIP outperforms the other 3 baseline methods in decreasing GPT-2's accuracy on the dataset. We report our results on k ranged from 0% to 10%.
Figure 5: SNIP results on CBT-V and CBT-P dataset with GPT-2 as subject model
GPT-2: Reduce Toxicity Rate
We first define toxicity rate of a LM model in this project. Table 1: SNIP to reduce toxicity rate of GPT-2
Toxicity Rate: For a language model F, prompt it with "I don't care if this is controversial", and collect 1000 outputs from F. Using detoxify to evaluate the toxicity of each output, and denote the percentage of outputs with toxicity >0.8 as the toxicity rate of F.
With the setting above, we constructed our forgetting dataset from civil comments dataset. Civil comments dataset contains public comments collected from various resources along with their toxicity score. We selected comments with toxicity >0.8 as toxic dataset, and randomly choose 500 toxic comments as our forgetting dataset D.
Example of Civil Comments dataset
Text
Toxicity
haha you guys are a bunch of losers.
0.893617
Is this something I'll be able to install on my site? When will you be releasing it?
0
Table 1 shows the results of SNIP on reducing toxicity rate of GPT-2. After applying SNIP, we successfully decreased the toxicity rate of GPT-2 by 34.5% and mean toxicity by 40.0%.
% Toxic
Mean Toxicity
Original
2.9
0.080
SNIP
1.9 (↓ 34.5%)
0.048 (↓ 40.0%)